Artificial Neural Networks: Transformers

The Transformer architecture has revolutionized Artificial Neural Networks (ANN), demonstrating unparalleled performance in natural language processing, speech recognition, image processing, and other areas that require efficient handling of sequence data. This architecture is the main catalyst behind the current boom in generative AI, which made models like GPT and Stable Diffusion mainstream names. In this note we will take a deep look into the original implementation of the transformer model, and will then expand it to some of the modern variants.
- The Basics
- Architectures
- Embeddings
- Transformers
So what’s the big deal?
The success of the Transformer model is largely driven by its innovative use of the attention mechanism, which allows it to both ingest and generate sequence data (e.g., text, audio, images) with greater efficiency than any of the preceding models. Unlike Recurrent Neural Networks (RNNs) that process sequence data serially, Transformers allow parallel processing and significantly improve both the training and inference times. The attention mechanism allows direct connections to be made between distant positions within long sequences, effectively capturing complex contextual relationships without running into unstable gradient problems. The scalability and flexibility of the Transformer architecture make it exceptionally well-suited for training on massive datasets and the creation of large “foundational” models.
The Architecture
In this note we will focus on the structure of the original Transformer presented in the seminal paper “Attention is All you Need”. This model was designed for text translation, a task where an input sequence may be transformed not only on the level of tokens, but also on the levels of sequence length and order. This structure is well suited as an introductory example because it includes all of the key building blocks of a Transformer, as some of the follow-up variants of the model (more on those later) essentially just removed some of the blocks in favor of others.
Structure Overview
In our example, the translation model follows the Encoder-Decoder design. The encoder stack transforms an input sequence (in the original language) into a context-rich vector representation that captures its meaning and essence within a latent space. The decoder then uses this vector representation to generate a coherent and contextually appropriate variable-length output sequence in the translated language.
The flow of the data through the model starts with a static embedding layer, which converts tokens into vectors of a fixed size. As an important step, positional encoding of each token is added to the embedding to allow the model to retain information on sequence order. These vectors are then processed by the encoder stack, which consists of multiple identical layers, each containing a multi-head self-attention sub-layer followed by a position-wise fully connected feed-forward network (FFN) sub-layer. The attention mechanism allows the model to weigh the relationship of different tokens in the input sequence. Token representations that are found to bear a significant dependency to each other are combined in a way that merges their semantic information. For example, for the token pair “purple house”, the representation of “house” gets modified in a way that make it gain a quality of “purpleness”, while “purple” gains some quality of “housiness”. Once the data exits the encoder stack, it is passed into the decoder stack, which has a very similar sub-layer structure, but includes an additional cross-attention mechanism to focus on relevant parts of the encoder’s output. Finally, the decoder’s output is transformed into a final probability distribution for the next token in the sequence through a combination of a linear layer and the softmax function.
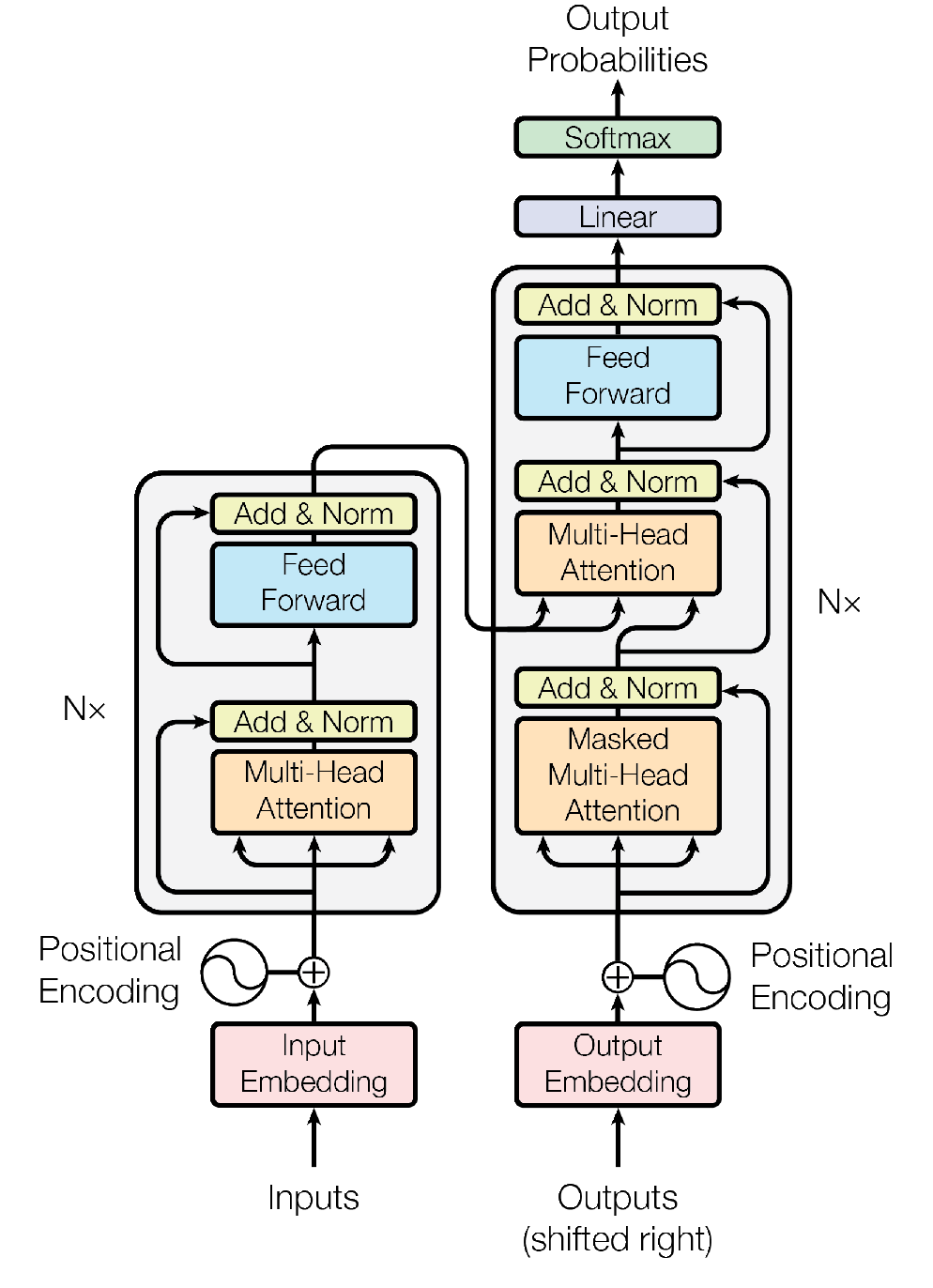
Reproduced from the original article.
Now that we have the lay of the land, let’s take a much deeper look at each of these elements and see how they work together.
Input Preprocessing
Training of an encoder-decoder model is performed using a parallel corpus, where the source sequences (e.g., sentences in the original language) are paired with their output sequences (e.g., sentence translations in the target language). A lot of work goes into the preparation of such a corpus, including removal of errors, proper alignment, and removal of poorly formed example pairs.
Both the encoder and the decoder stacks have their own inputs. The encoder takes in the source sequences and the decoder the target sequences (or the previously generated tokens during inference). Before the sequence pairs enter each of the stacks, they undergo several preprocessing steps to convert raw text into a format suitable for ingestion. First, the raw text is tokenized into either words, subwords, or even individual characters. Common tokenization methods include Byte Pair Encoding (BPE) and WordPiece, which break down words into subword units to handle out-of-vocabulary terms and reduce the vocabulary size.
Next, each token is mapped to a unique integer index within a predefined vocabulary matrix. This vocabulary is built from the full corpus and includes all possible tokens that the model might encounter. The vocabulary also incorporates special tokens, like “[START]”, “[END]” and “[PAD]” (used to pad sequences to a uniform length).
The maximum length of the input sequence the model can ingest in a single pass is called the context window (also referred to as the block size, especially in the context of training). It is a fixed hyperparameter set during the model design, and it is influenced by several factors. The attention mechanism has a computational complexity that scales quadratically with the sequence length, \( O(n^2) \), meaning that longer input sequences require significantly more memory and computational power. Therefore, the context window must be balanced with the available hardware resources to ensure efficient processing. Additionally, the nature of the input data and the specific requirements of the task can also influence the choice of the context window size. For example, tasks that involve understanding long documents or multiple sentences might benefit from a larger context window, while shorter tasks like single sentence classification might work well with smaller block sizes. To adhere to the context window limitations, shorter input sequences are padded by “[PAD]” tokens, while excessively long sequences are truncated.
Static Embedding
Once our text data is preprocessed, the token sequences are fed into the model where they first encounter the embedding layer. Here, each token in a sequence is converted into a dense distributed vector representation through an embedding matrix similar to the type produced by models like word2vec. Since Transformers take context words as input and then output a target word, the training of this embedding matrix, in essence, works very much like the training of a CBOW model (except with a lot of bells and whistles between the embedding matrix and the output). Also like in word2vec, this initial embedding is static, meaning that it does not change token representations based on their context. It is the job of the rest of the Transformer model to imbue these simple embeddings with rich contextual information.
Dimension Tracker:
As we move through the Transformer structure, I find it useful to keep track of various dimensions of the model. It helps us to better understand how information gets compressed and decompressed by the network, or what sort of projections are involved at each step. The specific numbers are taken from the original Transformer article (the base model), and are for illustration purposes only. In modern practice these numbers can be vastly different.
- \(d_{m} = 512\), “model size”, or the size of the embedded token representation that gets progressively updated with contextual information throughout the model.
- \(d_{b} = 100\), “block size”, not explicitly defined in the original publication, so I’ve picked a number that is distinctively different from other dimensions.
Positional Encoding
Unlike RNNs, Transformers do not consume input sequences in order. Instead, multiple input blocks can be processed in parallel. While this parallelization has many benefits, it also leads to the loss of information about token order. One of the key insights that enabled the development of the Transformer architecture is the realization that token order can be encoded into their embedding representation. If an embedding vector can efficiently represent latent qualities of a word, such as its relationship to the concept of “purple”, it can also encode the latent qualities of “first”, “second”, and so on.
Let’s imagine how we can design such a positional encoding approach. Our goal is to introduce a smooth representation of positions that can be directly added to the values in the embedding vector, creating features that would allow the model to infer the order and relative distances between tokens. The addition of the positional encoding information will result in the embedding vector to be shifted in the latent space in some ways. As a consequence, our positional encoding approach must satisfy two conflicting requirements: the magnitude of the positional encoding must be large enough for the model to uniquely resolve all possible positions (i.e., the shift should be noticeable), while also keeping the magnitude small enough to avoid overwhelming the semantic information in the embedding vector (i.e., the shift should not completely distort the original vector).
One trivial (but ineffective) approach to positional encoding is to introduce a single factor that is proportional to the order of the token in the sequence. This method fails, because as the sequence length increases, the magnitude of the encoding would eventually become too high and overshadow the semantic information in the embedding.
If a monotonic increasing factor strategy does not work, perhaps we could use some sort of a periodic function? If radio can encode your favorite song into the frequency of a periodic wave, we can certainly do the same for positional encodings! In fact, the original Transformer publication used such an approach, assigning each position in the input sequence a unique continuous encoding based on alternating sine and cosine functions of different frequencies. Using such trigonometric waves will limit the maximum shift in each dimension of our embedding vector within the (-1, 1) range.
Mathematically, for a given token position, \( pos \), the encoding is defined as follows:
$$ PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{\frac{2i}{d_m}}}\right) \\ PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{\frac{2i}{d_m}}}\right) $$
Here, \( d_m \) is the previously defined model size (i.e., the number of dimensions in the embedding vector), and \( i \) is a counter that goes between 0 and \( \frac{d_m}{2}\) (as a result, \( d_m \) must be an even number). This algorithm allows us to create a positional encoding vector of the same size as the embedding representation. The counter, \( i \), allows us to loop over all of the dimensions of the encoding vector and assign values to two dimensions at a time, a sine encoding for the even indexes, and a cosine encoding for the odd indexes.
To make this clearer, let’s express it in Python code:
def positional_encoding(sequence_length, embedding_size):
pos_matrix = np.zeros((sequence_length, embedding_size))
for token_position in range(0, sequence_length):
for counter in range(0, int(embedding_size/2)):
pos_matrix[token_position, 2*counter] = np.sin(token_position/(10000**((2*counter)/embedding_size)))
pos_matrix[token_position, 2*counter+1] = np.cos(token_position/(10000**((2*counter)/embedding_size)))
return pos_matrix
The reason for using both sine and cosine waves is to make the encoding more feature rich by increasing its variability. However, when trying to picture the trends in the different positional encoding dimensions, I find it easier to focus on one wave at a time. So let us look only at the even (sine-based) indexes in the vector, ignoring the odd dimensions for now. As an example, let’s set our embedding vector size, \( d_m \), to a total of 20 dimensions (10 odd, 10 even), and plot the positional encoding values as a function of the vector’s index. We will show the encodings for a sequence of 50 tokens, each represented by traces of different colors.
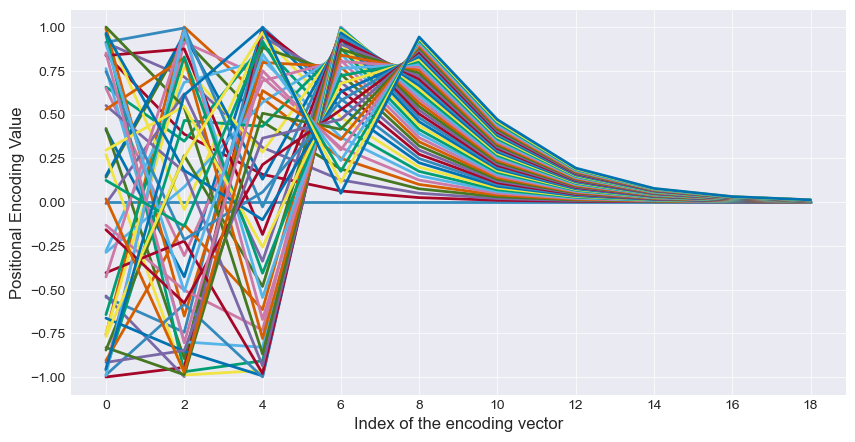
There is a lot going on here, but we can certainly see some periodic trends. A good analogy to describe this periodicity in positional encodings is that of a clock. A clock uses different hands to represent different units of time: seconds, minutes, and hours. Each hand moves at its own frequency: the second hand moves the fastest, the hour hand moves the slowest. Despite these different speeds, the positions of the hands collectively provide a unique representation of the exact time. Except in our example the clock has 20 hands! In the figure above, the wave in the first (leftmost) dimension has the highest frequency (shortest period). As such, the values in this dimension assigned to successive tokens will change very quickly, and will allow for the highest degree of their resolution. However, as this dimension “loops around the clock face” the fastest, some of the more distant tokens in the sequence have a high chance of getting a similar or an identical encoding value. For example, we see that at index = 0, at least 3 different tokens got an encoding value very close to -1. As we move through the vector indexes (from left to right in the figure), the frequency of the sine wave decreases. By approximately index = 6, the encoding values for our 50 tokens change so slowly that they fail to complete even half of the wave’s period (the values stop dipping into the negative range). By the last dimension, the positional encoding value for successive tokens barely changes. This last dimension offers very little resolution between close-by token positions, but it guarantees to have a unique value for every token in the sequence.
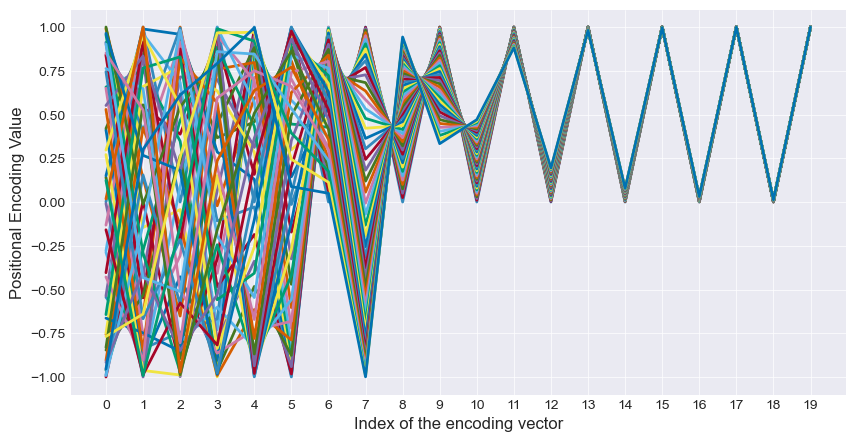
To complete the picture, let’s now add back our odd (cosine-based) indexes of the encoding vector. We can still see the same periodicity trends, except now each successive dimension is more distinct from its neighbors.
The beauty of this system is that it can easily handle sequences of very different lengths. Let’s expand our example from 50 tokens to 500:
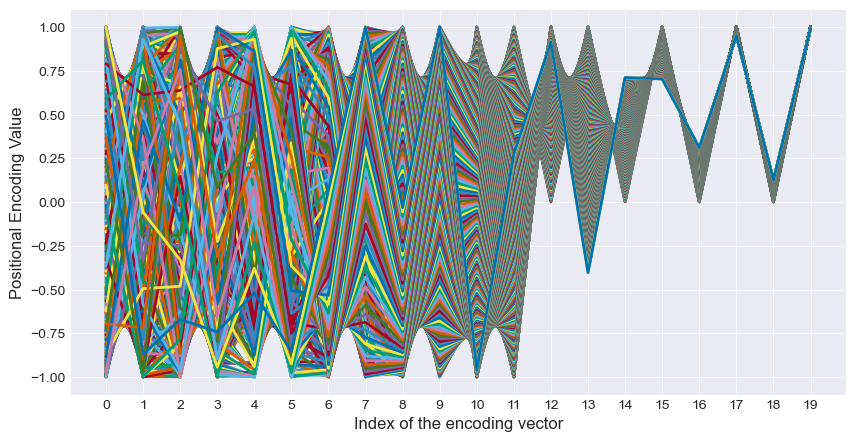
We see that our slower-moving dimensions easily pick up the slack and ensure that each of our 500 tokens still gets a unique representation, while the faster moving dimensions ensure that nearby tokens are easily resolvable from each other. And to top it all off, the effect that the positional encoding can have on the original vector is contained to the -1 to 1 range within each dimension.
Using pre-computed positional encodings, such as the one we described above, saves our model from introducing a lot of additional parameters. But this is not the only way to introduce positional information. Other approaches to positional encoding have also been developed, including systems where the information is treated as learnable parameters. Such systems allow the model to adaptively learn the best representation of positional information from the data, potentially improving performance on specific tasks.
The Encoder Stack
Once our embedded input sequence gets encoded with positional information, it gets passed into the Encoder stack. The purpose of the encoder is to transform input text sequences into contextually enriched representations that are packed with features that can be used for subsequent processing. This structure is composed of repeating encoder layers, each consisting of two main sub-layers: a multi-head self-attention mechanism and a position-wise fully connected FFN. Each of these sub-layers is wrapped in a residual connection followed by layer normalization.
Attention Mechanism
The attention mechanism allows the model to weigh how much two tokens affect each other semantically. Specifically within the encoder stack, we use the self-attention to gauge token relationships within the same sequence. Before we start covering it in detail, let’s introduce a few more dimensions to track.
Dimension Tracker:
- \(d_{m} = 512\), “model size”
- \(d_{b} = 100\), “block size”
- \(d_{k} = 64\), “key size”, generally applies to vectors in both Query (Q) and Key (K) matrices.
- \(d_{v} = 64\), “value size”, or the size of the Value (V) vectors. In the original Transformer model, it was set to the same value as \(d_{k}\), but it does not have to be.
In the attention mechanism, the token embedding matrix (size \( d_b \times d_m \)) gets projected onto 3 separate matrices: Query \((Q)\), Key \( (K) \), and Value \( (V) \). \( Q \) and \( K \) matrices usually share the same size, \( d_b \times d_k \), while the \( V \) matrix has a size \( d_b \times d_v \). These vectors are generated by multiplying the sequence of token embeddings by learned weight matrices \( W^Q \), \( W^K \), \( W^V \). Both \( d_k \) and \( d_v \) are usually smaller than \( d_m \), meaning that the information contained in the token embeddings gets projected onto a smaller number of dimensions. Functionally, this compression allows for all three of these matrices to select a specific set of features from the token embeddings space. It is useful to imagine that each of these three representations are trained to communicate a specific “message” to other tokens. The representations in the \( Q \) matrix send a message that says “I get modified by tokens that have these features”. Representations contained in the \( K \) matrix, on the other hand, send a message “I modify tokens that have these features”. When a \( Q \) vector from one token is similar to a \( K \) vector from another token, i.e., when their dot product is large, it means that their dependency on each other within a sequence is strong. For example, it is likely that adjectives and nouns that are next to each other in the sequence (e.g., “purple house”) will end up with similar Q and K representations, because usually such pairs are strongly dependent on each other.
The \( V \) matrix, in contrast, contains the actual values that get aggregated based on the attention scores computed from the dot products of \( Q \) and \(K \). The “message” that \( V \) sends can be imagined as “I modify tokens by introducing these features into them”. The values in \( V \) are essentially the information that is passed along to the next layer in the network.
Mathematically, the full attention mechanism can be expressed as follows:
$$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}} + \text{mask}\right)V $$
We see that our explanation hasn’t touched on a few elements, so let’s bring them in. After \( QK^T \) is calculated, we want to scale and normalize the product using the softmax function. It was found that passing the raw dot product to softmax often leads to vanishing gradients, so additional scaling by \(\sqrt{d_k}\) is usually added to contain their magnitude.
Prior to application of softmax we also apply an attention mask, which is used to control which positions in the input sequence should be attended to or ignored. The masks apply large negative values (e.g., negative infinity) to the attention scores of irrelevant positions (and zeroes everywhere else), effectively zeroing out the influence of irrelevant token relationships after the softmax operation. In the encoder, the attention mask is only used to ignore padding tokens.
Finally, the softmax’ed dot products multiply the \(V \) vectors to scale their relative effect on each other. At this stage, for each token in our sequence (let’s call it the “focus token” for brevity), we have \( d_b \) corresponding value vectors. Each of these vectors hold the features that will modify the focus token in a way that is proportional to the dot product of corresponding vectors from \( Q \) and \( K \). Importantly, the value vector of the focus token itself is contained here too. To bring the dimensionality of the attention’s layer output back into the sequence scale, we simply add up all of the value vectors for every token, yielding an updated semantic representation for each.
Going Multi-Head
What we have described so far represents a single “head” of the attention mechanism. It was found that running multiple instances of attention in parallel significantly improves performance. In multi-head attention, each head contains its own set of \( Q \), \( K \), and \( V \) matrices, providing each token with multiple representation subspaces.
For an equivalent number of parameters, a multi-head approach to attention is more efficient than a single-head approach due to the ability to compute the multiple heads in parallel. In addition, each head can focus on different parts of the input, allowing for richer and more redundant representation of token dependencies. The redundancy is especially important here, as each attention head essentially casts an independent vote on the perceived importance of the relationship between each token pair, making it an example of ensemble learning.
At this point, you may have noticed that we have two problems on our hands. In our example, each encoder layer contains an attention sub-layer with multiple independent heads (eight, to be specific), each producing it’s own attention-scaled \( V \) matrix. Each of these matrices now contain an independent representation of each of our tokens. How do we combine these eight matrices into a single representation? You may have noticed the second problem if you were paying a close attention to our dimension tracker. We’ve described that attention compresses our embedding representation from the larger \( d_m \) size to the smaller \( d_k \) size. But wouldn’t we expect that the \( V \) results should be decompressed back to the full representation size, \( d_m \)? Otherwise, our embedding representations might just keep getting smaller with each subsequent encoder layer. But the dimension tracker says that, at least in our specific example, \( d_v \) has the same decreased size as \( d_k \).
Both of these problems are solved in one swoop by simply concatenating the separate \( V \) matrices together. You will notice that \( d_v = d_m / h \), where h is the number of heads in multi-headed attention. In our example, it means that concatenating eight vectors of size 64 brings us back to the full embedding size of 512. To smooth out the merging of the concatenated representations, we finish off the attention sub-layer with one last multiplication with an “output” weight matrix, \( W_O\), of size \( d_b \times d_b \):
$$ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \ldots, \text{head}_h)W^O $$
where $$ \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) $$
This converts the data back to the dimensions of the original embedding matrix, \( d_b \times d_m \), except now the embedding representation of each token carries contextual information from all of the other tokens in the sequence.
Feed-Forward Network
Following the attention sub-layer, the resulting embedding representations are passed into a fully-connected FFN sub-layer. The structure of this FFN follows that of a simple multilayer perceptron, and in our specific example it consists of two linear layers with a ReLU activation function applied between them. This FFN serves several critical functions that enhance the model’s ability to represent and process complex patterns in the input data:
-
FFN introduces non-linearity into the model. While the self-attention mechanism is powerful, it is comprised solely of linear operations, which can limit its ability to capture complex relationships. By incorporating non-linear transformations through activation functions such as ReLU, the FFN enables the model to learn and represent more intricate patterns.
-
FFN is responsible for dimensionality transformation. Typically, the inner layers of the FFN increase the dimensionality of the representations (size \( d_{ff} \)) temporarily before reducing them back to their original size. This process allows the model to project the input data into a higher-dimensional space where more complex relationships can be discerned and then project it back to a lower-dimensional space, thereby enhancing the model’s expressive power.
-
It aids in feature extraction and interaction. By applying different linear transformations and non-linear activations, the FFN helps in extracting more abstract and high-level features from the input representations. These features encapsulate interactions between different dimensions of the input vectors that might not be explicitly captured by the self-attention mechanism alone. The FFN operates independently on each position in the input sequence, ensuring that the applied transformation is consistent across all tokens. This position-wise processing independence is crucial as it allows the same learned transformation to be applied uniformly, regardless of a token’s position in the sequence.
Dimension Tracker:
- \(d_{m} = 512\), “model size”
- \(d_{b} = 100\), “block size”
- \(d_{k} = 64\), “key size”, generally applies to vectors in both Query (Q) and Key (K) matrices.
- \(d_{v} = 64\), “value size”, or the size of the Value (V) vectors.
- \(d_{ff} = 2048\), size of the inner layer of the FFN. Expands the data representation to capture more intricate relationships.
Residual Connections and Layer Normalization
Transformer models can grow quite large, so we have to take special care to avoid gradient problems. For this purpose, both the multi-head attention and FFN sub-layers are wrapped in residual connections and their outputs are subjected to layer normalization.
When transitioning between the self-attention sub-layer and the FFN, the embedding representations can run into a problem. Within a given sequence, usually only a small proportion of tokens carry a significant relationship to each other, while most tokens are only loosely co-dependent. As a result, attention score matrices are generally sparse, i.e., the majority of attention scores are low. This sparseness causes an issue in backpropagation, where gradients associated with low scores cause a slow-down in the training of preceding nodes in the network. To avoid such vanishing gradients, residual connections (also known as skip connections) are added between the original input data and the layer outputs. Mathematically, the residual connection are very simple: all we do is add the original input values to the layer output. This ensures that the input values are never “forgotten” by a given layer, and that the model in general does not lose track of its original goals. It is also useful to wrap the FFN in a residual connection for the same reason.
Mechanistically, the main effect of residual connections is the improvement of the gradient flow, which mitigates the vanishing gradient problem by allowing gradients to bypass certain layers and flow directly through the network. This ensures that gradients remain large enough for effective backpropagation, leading to faster and more stable training. Residual connections also help prevent degradation, a problem where adding more layers can lead to higher training errors. By ensuring each layer contributes incrementally without degrading overall performance, residual connections maintain the effectiveness of deep networks.
As a side effect of repetitively adding input values to the outputs, we can run into the opposite problem: excessive growth of the gradient. To balance this effect out (and to generally stabilize the gradient), layer outputs (including the residuals) are subjected to layer normalization. It works by normalizing the activations of a layer across the features for each training example. This normalization is performed by adjusting and scaling the outputs to have a mean of zero and a variance of one, followed by a learned linear transformation to restore the model’s capacity to represent complex patterns.
For an input vector \( x \), layer normalization can be described as:
$$ \hat{x}_i = \frac{x_i - \mu}{\sqrt{\sigma^2 + \epsilon}} $$
Here, \( \mu \) is the mean of the input features, \( \sigma^2 \) is the variance, and \( \epsilon \) is a small constant added for numerical stability to prevent division by zero. After normalizing, the layer normalization scales and shifts the normalized values using learned parameters \( \gamma \) (scale) and \( \beta \) (shift), giving the final output:
$$ y_i = \gamma \hat{x}_i + \beta $$
Layer normalization ensures that the output distribution of each layer remains stable, making the training process more robust. It also improves gradient flow through the network by maintaining consistent input distributions, helping to keep gradients within a manageable range. Additionally, layer normalization contributes to model regularization, reducing overfitting by imposing a constraint on the outputs of each layer. This constraint encourages the model to learn more generalized patterns rather than memorizing the training data. It also enhances the model’s ability to handle varying batch sizes, as the normalization is applied independently of the batch dimension. This flexibility is particularly beneficial for tasks with fluctuating batch sizes or where real-time processing is required.
It should be noted, that many ANN architectures use batch normalization instead of layer normalization. In the batch approach, normalization occurs across the input data batch dimension rather than the model’s feature dimension. Transformers use layer normalization because the batch size in this model tends to vary a lot more and is generally a less relevant hyperparameter.
The Decoder Stack
While the purpose of the encoder stack is to transform input text sequences into contextually enriched embedding representations, the decoder stack is designed to generate text sequences from such continuous representations. Structurally, the decoder stack is very similar to the encoder, sharing many of the sub-layers, but it introduces additional mechanisms to effectively manage the generation process.
The decoder has a separate data input mechanism, which is structured in the same way as the input of the encoder. It includes the static embedding layer, with its own embedding matrix that is based on the output vocabulary (e.g., in the translated language). The decoder’s static embeddings also undergo positional encoding using the same method as in the encoder input. Following the data input mechanism, each layer in the decoder stack consists of three main sub-layers: a masked multi-head self-attention mechanism, a multi-head cross-attention mechanism, and a position-wise FFN.
The masked multi-head self-attention mechanism operates similarly to the self-attention mechanism in the encoder stack but includes a crucial distinction: the look-ahead mask. This triangular mask ensures that the model can only attend to earlier positions in the sequence and not to future positions.
The second sub-layer in each decoder is the multi-head cross-attention mechanism, which allows the decoder to focus on appropriate positions in the input sequence by creating attention vectors between the decoder’s current state and the encoder’s output. In cross-attention, the \( Q \) matrix comes from the decoder, while the \( K \) and \( V \) matrices come from the final encoder layer.
The rest of the decoder layer structure is identical to the encoder. The attention sub-layers are followed by a position-wise FFN, and each of the sub-layers is wrapped in residual connections with layer normalization.
Autoregression
The Transformer is an autoregressive architecture, meaning that at each inference pass it predicts one new token based on the available context. At each pass (also known as a time step), the prediction of the next token in the sequence is conditional both on the encoder input sequence and on all of the previously decoder-predicted output tokens. In the translation task example, the prediction of each output token depends on the knowledge of the full input sequence in the original language (to maintain the meaning of the sentence), and the previously generated translated tokens (to maintain proper gramatical structure of the sentence in the target language). The input sequence is ingested by the encoder all at once, hence there is no need for autoregression in this portion of the model. The autoregression behaviour comes solely from the decoder.
Training an encoder-decoder architecture involves the optimization of both stacks simultaneously. In this process, the input sequence is fed into the encoder unmasked, while the corresponding target sequence is fed into the decoder with a look-ahead mask, making sure that the decoder’s self-attention block cannot rely on the contextual information from future tokens. Prior to the input into the decoder, the target sequence is shifted to the right by one position by introducing a [START] special token in the first position. An [END] token is also added to the end of the sequence, to teach the model when to stop generation. This right-shifted “context” sequence is used as the input to the decoder during training, while the original (unshifted) sequence serves as the expected output for evaluation of the cost function. This shift between the decoder’s context and the expected output during training teaches the decoder to predict new tokens. For example, on the first inference pass, the decoder only has the [START] token as the context. The model is trained to predict the first word of the translated sequence using the full encoder context and just the [START] token. On the second pass, the decoder output context is expanded to include both the [START] token and the first token predicted by the decoder, and so on for future passes. This goes on until the model decides that an [END] token is the most likely prediction.
Linear Layer and Softmax
We are almost ready for the model to make the final prediction. Exiting the decoder stack, the data passes though a linear layer and the softmax function. These components are responsible for transforming the decoder’s outputs into a probability distribution over the vocabulary.
The linear layer simply multiplies the decoder output by an unembedding weight matrix and adds a bias vector. Since the size of the representation matrix is \( d_b \times d_{m} \), multiplying it by a weight matrix of size \( d_{m} \times V \) (with \(V\) being the size of the vocabulary), gets us to a vocabulary logits matrix of size \( d_b \times V \). This transformation projects the decoder’s output into a space where each dimension corresponds to a word in the vocabulary. Applying the softmax function then converts the logits into a probability distribution over the vocabulary. While the logits matrix has \( d_b \) number of vectors in the “sequence length” dimension, all of them do not matter except for the vector in the last non-padded position. This position corresponds to the probability distribution of the newly predicted token. As a result, most implementations unembed only this last vector, and not the whole representation matrix.
Output sampling
Once softmax produces a probability distribution over the vocabulary, a single token must be sampled from this distribution. Depending on the intended behaviour of the model, a few sampling methods can be used:
- Argmax: The simplest method is to select the token with the highest probability. This is known as greedy decoding. It always picks the most likely token at each step.
- Random Sampling: Instead of always picking the highest probability token, you can sample from the probability distribution. This introduces randomness and can generate more diverse outputs.
- Top-k Sampling: This method limits the sampling to the top k tokens in the probability distribution, reducing the chance of selecting unlikely tokens.
- Top-p (Nucleus) Sampling: Instead of limiting the number of tokens, this method considers the smallest set of tokens whose cumulative probability exceeds a threshold p, ensuring that the selected tokens have a combined probability mass of at least p.
- Beam Search: This is a more complex method that maintains multiple candidate sequences (beams) and explores them simultaneously to find the most likely sequence.
The choice of the sampling method can significantly affect the model’s output. Greedy decoding makes each output more predictable and reproducible, but may make generative models sound repetitive. When output diversity is important, methods like top-k and top-p sampling introduce the needed variability.
Modern Transformer Variants
Since the introduction of the original Transformer model, numerous improvements and adaptations have been developed to enhance performance, scalability, and efficiency across various applications. Here, we discuss some of the most notable modern designs that build upon the foundation of the Transformer architecture.
BERT
BERT (Bidirectional Encoder Representations from Transformers), developed by Google, represents a significant evolution in transformer-based models. Unlike the original Transformer which focuses on sequence-to-sequence tasks like translation, BERT is designed to generate deep bidirectional representations by conditioning on both left and right contexts in all layers. This makes BERT particularly effective for tasks that require understanding the context of a word within a sentence.
BERT’s architecture uses only the encoder stack of the original Transformer model. It introduces a novel pre-training objective: the Masked Language Model (MLM), where some tokens in the input are masked at random, and the model is trained to predict these masked tokens. Additionally, BERT uses the Next Sentence Prediction (NSP) task, where the model is trained to predict if two given sentences are sequential in the original text, enhancing its ability to understand the relationships between sentences.
GPT
GPT (Generative Pre-trained Transformer), developed by OpenAI, is another groundbreaking model that diverges from the encoder-decoder structure by using only the decoder part of the Transformer architecture. GPT is an autoregressive model, meaning it generates text one token at a time, conditioning each token on the previous ones. This approach allows GPT to excel in tasks that involve text generation, such as conversational agents and creative writing.
GPT-3, a notable version of this model, has 175 billion parameters, making it one of the largest language models to date. The model’s massive size and extensive pre-training on diverse internet text enable it to perform a wide range of natural language tasks with impressive proficiency, even without task-specific fine-tuning.
T5
T5 (Text-To-Text Transfer Transformer), also developed by Google, proposes a unified approach to handling different NLP tasks by framing them all as text-to-text problems. This means that both the input and output are treated as text strings, allowing the same model, objective, training procedure, and decoding process to be used across various tasks.
T5 uses a modified version of the Transformer architecture and introduces several improvements, such as the use of relative positional encodings and the exploration of different architectural modifications. The model is pre-trained on a diverse range of text-to-text tasks, enabling it to generalize well across different NLP applications.
Efficient Transformers
As Transformer models grow larger, their computational requirements increase significantly. Efficient Transformers aim to address these scalability issues by reducing the computational and memory costs associated with the attention mechanism. Some of the key innovations in this area include:
- Sparse Attention: Techniques like Longformer and BigBird introduce sparse attention mechanisms that limit the number of tokens each token attends to, reducing the quadratic complexity of the original attention mechanism to linear or near-linear complexity.
- Linformer: This model approximates the full attention matrix with a low-rank matrix, significantly reducing the memory footprint and computational cost.
- Performer: The Performer model uses kernel-based methods to approximate the softmax attention mechanism, enabling linear time complexity and making it feasible to handle much longer sequences.
Vision Transformers
Transformers have also made significant strides in the field of computer vision. Vision Transformers (ViT) apply the Transformer architecture to image classification tasks by treating image patches as sequence tokens. This approach has shown competitive performance compared to traditional convolutional neural networks (CNNs) on various image recognition benchmarks.
ViTs divide an image into fixed-size patches, embed each patch into a vector, and then process the sequence of patch embeddings using a standard Transformer encoder. This method allows ViTs to capture long-range dependencies and global context in images, which are challenging for CNNs.
Wrap-up
The evolution of Transformer models continues to push the boundaries of what is possible in machine learning and AI. From their initial application in natural language processing to their expansion into vision and other domains, Transformers have proven to be a versatile and powerful architecture. Modern variants like BERT, GPT, T5, and various efficient Transformer designs have further enhanced their capabilities, making them indispensable tools in the AI researcher’s toolkit.
- The Basics
- Architectures
- Embeddings
- Transformers